0 引言
在航空航天、医疗服务、地质勘探等复杂应用领域,需要处理的数据量急剧增大,需要高性能的实时计算能力提供支撑。与多核处理器相比,众核处理器计算资源密度更高、片上通信开销显着降低、性能/功耗比明显提高,可为实时系统提供强大的计算能力。
在复杂应用领域当中,不同应用场景对计算的缓冲需求可能不同。例如,移动机器人在作业时,可能需要同时执行路径规划、目标识别等多个任务,这些任务需要同时执行;在对遥感图像处理时,需要对图像数据进行配准、融合、重构、特征提取等多个步骤,这些步骤间既需要同时执行,又存在前驱后继的关系。因此,基于众核处理器进行计算模式的动态构造,以适应不同的应用场景和应用任务成为一种新的研究方向。文献[1]研究了具有逻辑核构造能力的众核处理器体系结构,其基本思想是基于多个细粒度缓冲处理器核构建成粗粒度逻辑核,将不断增加的处理器核转化为单线程串行应用的性能提升。文献提出并验证了一种基于类数据流驱动模型的可重构众核处理器结构,实现了逻辑核处理器的运行时可重构机制。文献 提出了一种支持核资源动态分组的自适应调度算法,通过对任务簇的拆分与合并,动态构建可弹性分区的核逻辑组,实现核资源的隔离优化访问。
GPGPU(General - Purpose Computing on GraphicsProcessing Units)作为一种典型的众核处理器,有关研究多面向单任务并发执行方面的优化以及应用算法的加速。本文以GPGPU为平台,通过研究和设计,构建了单任务并行、多任务并行和多任务流式处理的多计算模式处理系统。
1 众核处理机
1.1 众核处理机结构
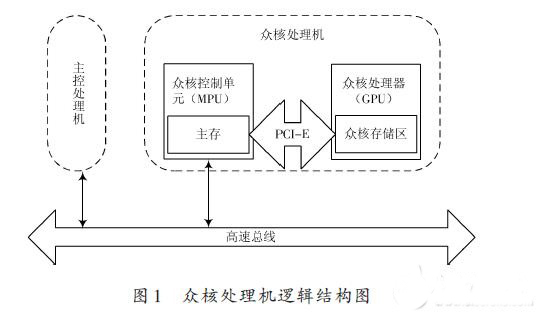
众核处理机是基于众核控制单元(MPU)与众核处理器(GPGPU)相结合的主、协处理方式构建而成,其逻辑结构如图1所示。众核处理机由众核控制单元和众核计算单元两部分组成,其中众核控制单元采用X86结构的MPU,与众核计算单元之间通过PCI-E总线进行互连。
1.2 CUDA流与Hyper-Q
在统一计算设备架构(Compute Unified Device Ar-chitecture,CUDA)编程模型中,CUDA流(CUDA Stream)表示GPU的一个操作队列,通过CUDA流来管理任务和并行。CUDA 流的使用分为两种:一种是CUDA 在创建上下文时会隐式地创建一个CUDA流,从而命令可以在设备中排队等待执行;另一种是在编程时,在执行配置中显式地指定CUDA 流。不管以何种方式使用CUDA流,所有的操作在CUDA流中都是按照先后顺序排队执行,然后每个操作按其进入队列的顺序离开队列。换言之,队列充当了一个FIFO(先入先出)缓冲区,操作按照它们在设备中的出现顺序离开队列。
在GPU 中,有一个CUDA 工作调度器(CUDA WorkDistributor,CWD)的硬件单元,专门负责将计算工作分发到不同的流处理器中。在Fermi架构中,虽然支持16 个内核的同时启动,但由于只有一个硬件工作队列用来连接主机端CPU 和设备端GPU,造成并发的多个CUDA 流中的任务在执行时必须复用同一硬件工作队列,产生了虚假的流内依赖关系,必须等待同一CUDA流中相互依赖的kernel执行结束,另一CUDA流中的ker-nel才能开始执行。而在Kepler GK110架构中,新具有的Hyper-Q特性消除了只有单一硬件工作队列的限制,增加了硬件工作队列的数量,因此,在CUDA 流的数目不超过硬件工作队列数目的前提下,允许每个CUDA流独占一个硬件工作队列,CUDA流内的操作不再阻塞其他CUDA流的操作,多个CUDA流能够并行执行。